Unlocking the Power of Big Data: A Deep Dive into MapReduce
Related Articles: Unlocking the Power of Big Data: A Deep Dive into MapReduce
Introduction
With great pleasure, we will explore the intriguing topic related to Unlocking the Power of Big Data: A Deep Dive into MapReduce. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unlocking the Power of Big Data: A Deep Dive into MapReduce
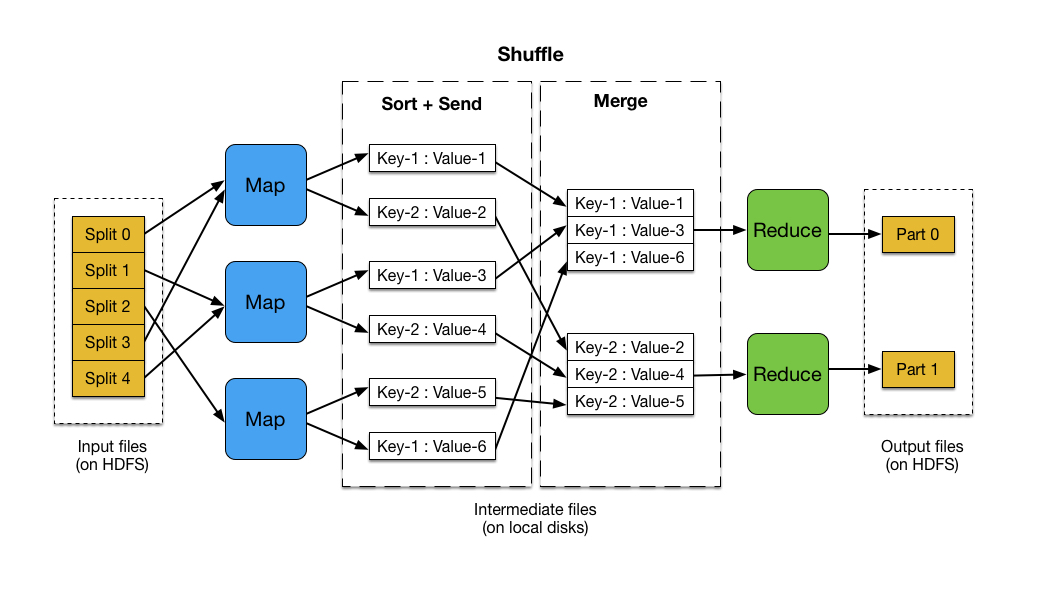
The exponential growth of data in our digital age has presented both unprecedented opportunities and daunting challenges. Handling and extracting meaningful insights from massive datasets, often referred to as "big data," requires innovative approaches and powerful tools. One such tool, MapReduce, has emerged as a cornerstone of distributed computing, enabling efficient processing of vast amounts of data across multiple machines.
This article delves into the intricacies of MapReduce, exploring its fundamental principles, practical applications, and the advantages it offers in harnessing the power of big data.
Understanding the Essence of MapReduce
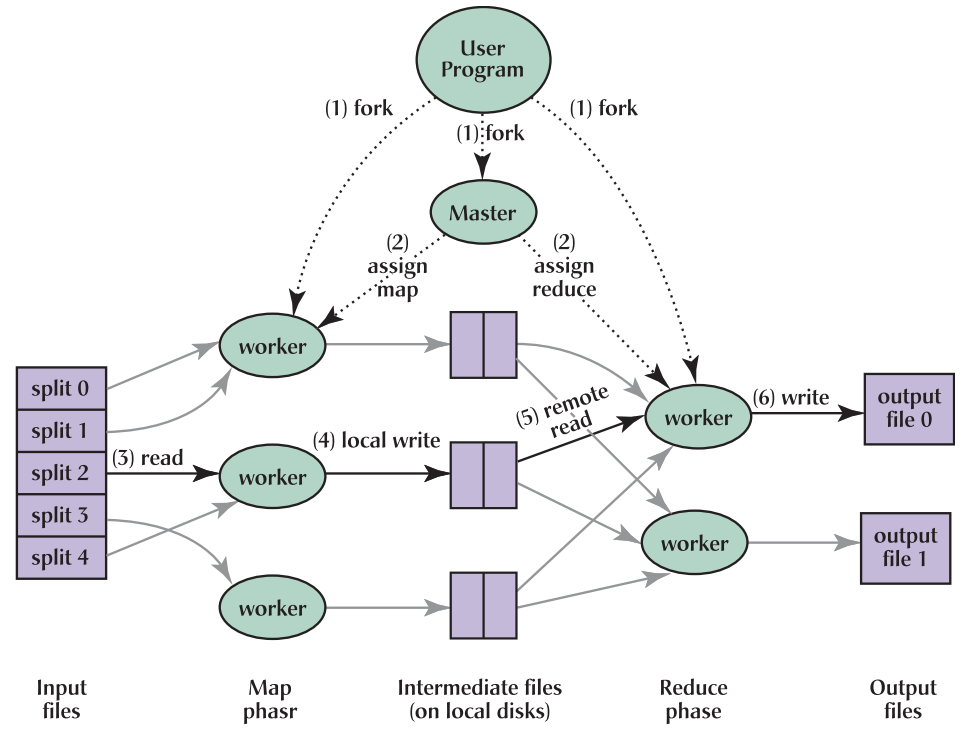
MapReduce, a programming model and a framework for distributed computing, simplifies the process of parallel data processing. It breaks down complex tasks into two distinct phases: map and reduce.
-
Map Phase: This phase involves processing individual data elements, transforming them into key-value pairs. Imagine a scenario where you have a massive dataset of customer purchase records. The map phase could extract relevant information, such as customer ID, purchase date, and product category, creating key-value pairs for each record.
-
Reduce Phase: The reduce phase aggregates the key-value pairs generated in the map phase. This aggregation process typically involves applying functions like summation, averaging, or counting to derive meaningful insights. In our customer purchase example, the reduce phase could aggregate the purchase records for each customer, calculating their total spending or average purchase frequency.
The Power of Parallelism
The real strength of MapReduce lies in its ability to distribute the processing workload across multiple machines. This parallel execution significantly accelerates the processing time, making it feasible to handle massive datasets that would be impossible to process on a single machine.
Practical Applications of MapReduce
MapReduce finds applications in a wide range of domains, including:
-
Web Search: Search engines rely heavily on MapReduce to process massive amounts of web data, indexing web pages, ranking search results, and analyzing user search queries.
-
Social Media Analysis: MapReduce empowers social media platforms to analyze user interactions, identify trends, and personalize content recommendations.
-
E-commerce: E-commerce giants utilize MapReduce for tasks such as fraud detection, customer segmentation, and product recommendation systems.
-
Scientific Research: Researchers in various fields, including genomics, climate science, and astrophysics, leverage MapReduce to analyze large datasets and extract valuable insights.
-
Financial Analysis: Financial institutions use MapReduce to analyze market data, identify patterns, and assess risks.
Key Advantages of MapReduce
-
Scalability: MapReduce scales effortlessly, allowing for processing of massive datasets by adding more machines to the cluster.
-
Fault Tolerance: The framework is designed to handle node failures gracefully, ensuring data integrity and processing continuity.
-
Ease of Programming: MapReduce simplifies parallel programming, enabling developers to focus on the core logic of their applications rather than low-level distributed computing details.
-
Flexibility: The framework supports various data formats and allows for customization of map and reduce functions to suit specific needs.
Beyond the Basics: Understanding the Landscape of MapReduce
While MapReduce has been a revolutionary force in big data processing, it’s essential to acknowledge the evolution of the landscape. Several other frameworks and technologies have emerged, each with its own strengths and weaknesses. Here’s a brief overview:
-
Hadoop: A widely adopted open-source framework that provides a platform for running MapReduce jobs. It offers a distributed file system (HDFS) for storing and accessing large datasets.
-
Spark: A faster and more versatile framework that supports a wider range of processing paradigms, including batch processing, real-time processing, and machine learning.
-
Apache Flink: A real-time processing framework that excels at handling streaming data, enabling applications like fraud detection and anomaly detection.
-
Apache Beam: A unified programming model that allows developers to write data processing pipelines that can run on various execution engines, including Apache Spark, Apache Flink, and Google Cloud Dataflow.
FAQs: Addressing Common Queries about MapReduce
Q: What are the limitations of MapReduce?
A: While MapReduce offers significant advantages, it also has certain limitations:
-
Data Locality: MapReduce often involves moving data across the network, which can be inefficient for certain workloads.
-
Limited Flexibility: The framework’s rigid structure can sometimes hinder the implementation of complex algorithms.
-
Data Skew: Uneven data distribution can lead to performance bottlenecks, as some machines may become overloaded while others remain idle.
Q: How does MapReduce differ from other big data processing technologies?
A: MapReduce is a specific programming model and framework, while other technologies like Spark and Flink offer more versatile processing paradigms. Spark, for instance, supports both batch and real-time processing, while Flink excels at handling streaming data.
Q: What are the future directions of MapReduce?
A: While MapReduce has paved the way for distributed computing, newer frameworks like Spark and Flink are gaining popularity due to their enhanced performance and flexibility. However, MapReduce remains a valuable tool for specific applications and continues to evolve with advancements in distributed computing technologies.
Tips for Implementing MapReduce
-
Optimize Data Partitioning: Ensure data is partitioned efficiently across machines to maximize parallelism and minimize data movement.
-
Minimize Network Traffic: Design your map and reduce functions to minimize data transfer between machines, reducing network overhead.
-
Handle Data Skew: Implement strategies to address data skew issues, such as using combiners to reduce the number of intermediate key-value pairs.
-
Leverage Data Locality: When possible, process data on the same machine where it is stored to reduce network latency.
-
Monitor Performance: Regularly monitor the performance of your MapReduce jobs to identify bottlenecks and optimize performance.
Conclusion: The Enduring Legacy of MapReduce
MapReduce has revolutionized the way we process and analyze massive datasets. Its simplicity, scalability, and fault tolerance have made it a cornerstone of big data processing. While newer frameworks have emerged, MapReduce remains a valuable tool for specific applications and continues to influence the evolution of distributed computing technologies. As the world of big data continues to expand, the principles and concepts behind MapReduce will undoubtedly continue to play a crucial role in unlocking the power of data and driving innovation across various domains.





Closure
Thus, we hope this article has provided valuable insights into Unlocking the Power of Big Data: A Deep Dive into MapReduce. We thank you for taking the time to read this article. See you in our next article!